Pekiştirmeli Öğrenme - Bölüm 4: Dinamik Programlama
Dinamik Programlama
Dinamik Programlama terimi (Dynamic Programming-DP), bir Markov Karar Süreci (Markov Decision Process) ortamının mükemmel bir modelinde uygun politikayı(optimal policy) hesaplama amacı ile kullanılacak algoritmaların bütününü ifade eder. Klasik DP algoritmaları, büyük hesaplama maliyeti nedeniyle Pekiştirmeli Öğrenmede sınırlı bir kullanıma sahiptir. Ancak yine de teorik olarak önemlidirler.
DP’nin ve genel olarak Pekiştirmeli Öğrenmenin temel fikri, iyi politikalar arayışını organize etmek ve yapılandırmak için değer fonksiyonlarının kullanmasıdır. Bölüm 3: Sonlu Markov Karar Süreçlerinde bahsedildiği gibi, burada Bellman Uygunluk Denklemleri ile en uygun değer fonksiyonlarını \(v_{*}\) veya \(q_{*}\) ifadelerini bulduğumuz zaman kolayca en uygun politikayı elde edebiliriz.
\[\begin{align*} v_{*}(s) &= \max_{a}\mathbb{E}[R_{t+1}+\gamma v_{*}(S_{t+1}) | S_t=s,A_t=a] \\ &=\max_{a}\sum_{s',r}p(s',r|s,a)[r+\gamma v_{*}(s')] \\ q_{*}(s,a)&= \mathbb{E}[R_{t+1}+\gamma \max_{a'}q_{*}(S_{t+1},a')|S_t=s, A_t=a] \\ &=\sum_{s',r}p(s',r|s,a)[r+\gamma\max_{a'}q_{*}(s',a')] \end{align*}\]Politika Değerlendirmesi (Tahmin)
Herhangi bir \(\pi\) politikası için durum değer fonksiyonunu bulmaya literatürde politika değerlendirmesi yahut tahminleme denmektedir.
\[\begin{align*} v_\pi (s)&\doteq \mathbb{E_\pi} [G_t |S_t=s] \\ &= \mathbb{E_\pi} [R_{t+1} + \gamma {G_{t+1}} |S_t=s] \\ &= \mathbb{E_\pi} [R_{t+1} + \gamma v_\pi {S_{t+1}} |S_t=s] \\ &= \sum_a \pi (a|s) \sum_{s',r}p(s',r|s,a)[ r + \gamma v_\pi(s') ] \end{align*}\]Çevre dinamiklerinin tümüyle bilindiği durumlarda değer fonksiyonunu iterasyonlar ile bulmak mümkün olmaktadır. Bellman Güncelleme Kuralı kullanılarak değer fonksiyonu bulunabilir. Bu yönteme İteratif Politika Değerlendirmesi (Iterative Policy Evaluation) denmektedir.
\[\begin{align*} v_{k+1}(s)&\doteq \mathbb{E_\pi} [R_{t+1} + \gamma v_k {S_{t+1}} |S_t=s] \\ &= \sum_a \pi(a|s)\sum_{s',r}p(s',r|s,a)[ r + \gamma v_k(s') ] \\ \end{align*}\] \[s \in S\]Politika Geliştirme
Değer fonksiyonları, daha iyi politikalar geliştirmeye yardımcı olmak amacıyla geliştirilmektedir. Belirli bir fonksiyon için rastgele belirlenen bir politikaya göre, \(s\) durumu(state)nun ne kadar iyi bir durum olduğu bilinmeye çalışılacaktır. Bunu öğrenmenin yolu \(s\) durumunda \(a\) eylem(action)ini uygulayarak mevcut \(\pi\) politikasını takip etmektir. Bu şekilde davranarak bulunacak değer şu şekilde belirlenebilir;
\[\begin{align*} q_\pi(s,a) &\doteq \mathbb{E}[R_{t+1}+ \gamma v_\pi(S_{t+1})| S_t=s,A_t=a] \\ &=q_\pi (s,a) = \sum_{s',r} p(s',r|s,a)[r+\gamma v_\pi (s')] \end{align*}\]Anahtar kriter bu yeni değerin \(v_{\pi}(s)\)’ten büyük olup olmadığıdır. Eğer büyükse, politikanın seçtiği eylem doğrudur denilebilir ve bu eylemi seçmesi teşvik edilebilir. Bu durumda yeni politika genel olarak daha iyi olur. Bu tür gelişimlere Politika Geliştirme teoremi denir. Bu teorem baz alınarak, \(\pi\) politikası şu şekilde ele alınabilir;
\[\begin{align*} \pi'(s) &= argmax_a q_\pi(s, a) \\ &= argmax_a \mathbb{E}[R_{t+1} + \gamma v_\pi(S_{t+1}) | S_t=s, A_t=a] \\ &= argmax_a \sum_{s',r} p(s',r|s,a)[r+\gamma v_\pi (s')] \end{align*}\]\(argmax_a\) bu noktada, politikanın kısa vadede beklentisi en yüksek olan eylemi seçmesini sağlar.
Politika İterasyonu
Politikayı geliştirmek için \(v_\pi\) değer fonksiyonu kullanıldıktan sonra daha iyi bir \(\pi\) ortaya çıkarmak için yeni \(v_{\pi'}\) öğrenilir ve iterasyon tekrarlanır. Bu gelişimler şu şekilde gösterilir:
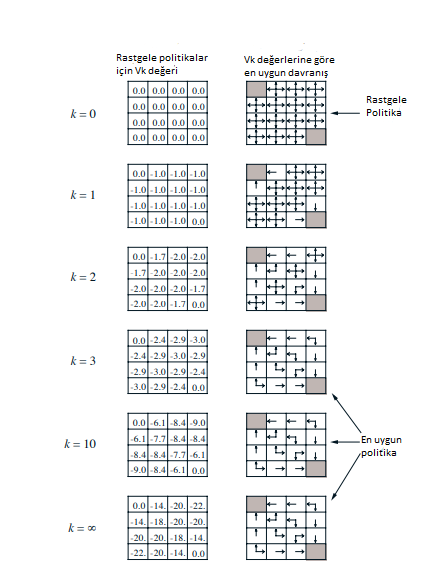
Şekil 4.1 : Küçük bir gridworld’de iteratif politika değerlendirmesinin yakınsaması.Sol sütun rastgele politika için durum-değer işlevinin yaklaşık dizisi (tüm işlemler eşit olasılıkla).Sağ sütun, değer işlevi tahminlerine karşılık gelen açgözlü politikaların dizisidir (maksimuma ulaşan tüm eylemler için oklar gösterilir ve gösterilen sayılar iki önemli basamağa yuvarlanır).Son politikanın sadece rastgele politika üzerinde bir gelişme olması garanti edilir, ancak bu durumda bu ve üçüncü yinelemeden sonraki tüm politikalar en uygunudur.
\begin{align} \pi_0 \xrightarrow{\text{E}} v_{\pi_0} \xrightarrow{\text{I}} \pi_1 \xrightarrow{\text{E}} v_{\pi_1} \xrightarrow{\text{I}} \pi_2 \xrightarrow{\text{E}} \ldots \xrightarrow{\text{I}} \pi_* \xrightarrow{\text{E}} v_* \end{align}
\(\xrightarrow{\text{E}}\) Değerlendirme (Evaluation)
\(\xrightarrow{\text{I}}\) Gelişim (Improvement)

Değer İterasyonu
Politika iterasyonunun bir dezavantajı ise iterasyon sırasında her bir durum için politika değerlendirmesi yapmasıdır. Bu değerlendirme fazladan efor sarfedilmesine yol açmaktadır. Eğer politika değerlendirmesi iteratif olarak yapılırsa \(v_\pi\)’ye yakınsama sadece sınırda gerçekleşir.
Politika değerlendirmesi, her bir durum güncellemesi yapıldıktan sonra durdurulabilir. Bu algoritmaya Değer İterasyonu denmektedir.
\[\begin{align*} v_{k+1}(s)&\doteq\max_a \mathbb{E}[R_{t+1} + \gamma v_k(S_{t+1})|S_t=s, A_t=a] \\ &=\max_a \sum_{s',r}p(s', r|s, a)\big[r + \gamma v_k(s')\big] \end{align*}\]Değer İterasyonu, değer fonksiyonunun değişiminin çok küçük olduğu durumlarda sonlandırılabilir.

Asenkron Dinamik Programlama
Şu ana kadar bahsedilen DP yöntemlerinin önemli bir dezavantajı, MDP’nin tüm durum kümesi üzerinde çalışıyor olması. Örneğin tavla oyununda \(10^{20}\)’den fazla durum vardır. Böyle MDP ortamları için tek bir tarama işlemi saniyede bir milyon güncelleme yapılsa dahi bin yıllar sürebilir.
Asenkron DP algoritmaları, durum kümesinin güncellemelerinin sistematik olmayacak şekilde yapılmasıdır. Bu şekilde paralel çalışabilen algoritmalar hazırda bulunan durum değerlerini kullanarak güncelleme yapabilmektedirler. Bazı değerler birden çok kez güncellense dahi, bu yapı hızlı yakınsama sağlayabilir.
Elbette bu esneklik daha az hesaplama anlamına gelmeyecektir. Esnekliği, algoritmanın gelişim oranını iyileştirme ve durumları belli bir yapıya göre seçebilme gibi avantajlar sağlamaktadır. Bazı durumların güncellemesine ihtiyaç duymayabilir hatta bazı durumlarda ise o durumları atlayarak hız konusunda verim dahi artırılabilir.
Genelleştirilmiş Politika İterasyonu
Politika değerlendirme ve Politika geliştirme güncellemelerin sonunda en uygun değer ve en uygun politikaya yakınsamaktadır. Bu değerlendirme ve geliştirme süreçlerinin etkileşime girmesine ilişkin genel fikre Genelleştirilmiş Politika İterasyonu (GPI) denmektedir.
Zira, değer fonksiyonu güncel politikayı, güncel politika değer fonksiyonunu direkt etkilemektedir. Pekiştirmeli Öğrenme’de kullanılan bütün algoritmalara bu anlamda GPI denilebilir.
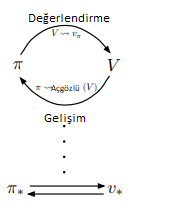
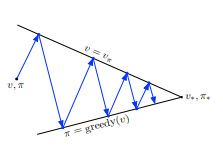
GPI’da değerlendirme ve geliştirme kısımları hem rekabet hem de işbirliği olarak görülebilir. Birbirlerini etkilemeleri anlamında rekabet ederler fakat asıl amaç en uygun değer fonksiyonu ve en uygun politikayı ortaya çıkarmaktır.
Dinamik Programlamanın Verimliliği
Dinamik Programlama çok büyük problemler için pratik olmayabilir. Fakat MDP’leri çözen diğer yöntemlere oranla DP yöntemleri oldukça verimlidir. Fakat DP yöntemlerinin uygulanabilirliği, durum uzayının katlanarak büyüdüğü ve bunun sonucunda boyutsallık probleminin oluştuğu problemlerde sınırlı olacaktır. Bu sorunların nedeninde DP’nin çözüm yöntemleri ile ilgisi yoktur. Hatta durum sayısının büyük olduğu durumlarda DP, doğrudan arama (Linear search) ve doğrusal programlama (Linear Programming) gibi yöntemlere göre avantajlıdır.