Pytorch ile Derin Ögrenme - Bölüm 1: Pytorch ile Logistic Regression
Pytroch-ile-Logistic-Regression
Pytorch Nedir?
Zaman içerisinde makine ögrenmesi algoritmaların problemlere çözüm olmasının azalmasıyla birlikte, verilerin boyutunun her geçen gün artmasıyla Deep Learning algoritmaların kullanılması da artmaktadır. Bu kapsam da ses tanıma, görüntü işleme, görüntü sınıflandırma, nesne tanıma vb. çalışmalarda derin ögrenme algoritmaları daha başarılı sonuçlar üretmiştir. Tüm bu işler yapılırken aynı zaman da zaman dan kazanmak için hız gereksinimi dogmuştur. Bu bağlamda bakıldığında Pytorch derin ögrenme algoritmarın hızlı çalışmasını sağlayan açık kaynak bir python kütüphanesidir.
Pytorch ekran kartlarını kullanabilen ve böylelikle sağladığı hız bakımından oldukça popüler bir kütüphanedir.Pytorch’un başarılı olmasının nedenlerinden bir tanesi de sinir ağı modelleri zahmetsizce oluştura bilmesidir. Pytorch aynı anda CPU ve GPU gibi arka planda başka işler için yapıları kullanabilir. Pytorch’un Numpy kütüphanesine benzer kendi bir Tensor yapısı mevcuttur.
Logistic Regression Nedir ve Nasıl Çalışır?
Logistic Regression sınıflandırma modelleri için kullanılabilen 0 ve 1 gibi akla gelen ilk sınıflandırma regressionlarında bir tanesidir. Aynı zamanda yapay sinir ağları içinde bir temel oluşturmaktadır. Logistic regression ile birlikte sinir ağı kelimesinden bahsedilmeye başlanılmıştır. Derin ögrenme algoritmalarından farkı tek katmanlı olmasıdır. İlerleyen yazılarda katman ve derin kelimerin anlamlarından da bahsedilecektir.
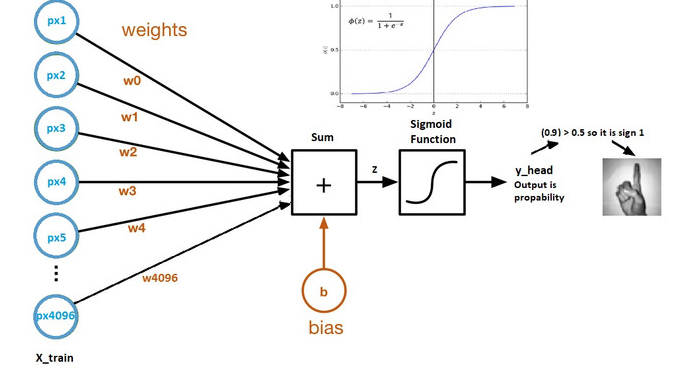
Genel Olarak Logistic Regression girdilerin weight’lerin transpozu ile çarpılarak üzerine de bias eklenerek çalışmaktadır.
z=(w.t)x+b
Bu aşamadan sonra a çıktısı bir tane activasyon fonksiyonuna eklenerek y_head(tahmin) değeri alde edilmiş olur.
y_head(tahmin)=sigmoid(z)
Kısaca Logistic Regressiondan bahsettikten sonra artık Pytorch ile nasıl model oluşturulur adım adım ilerleyelim.
Dataset
Kullanılan veri seti kaggle’dan elde edilmiştir. Link bilgisi aşağıdaki gibidir.
https://www.kaggle.com/datasets/zalando-research/fashionmnist
Veri setinden kısaca bahsedilecek olursa içerisinde 28*28 pikselden oluşan içerisinde 60000 train(eğitim) ve 10000 test verilerinden oluşan içerisinde 10 sınıf barındırıan bir veri setidir. Burada piksel değerleri 0 ile 255 arasındadır. Her bir resim 784 pikselden oluşmaktadır.
Adım adım önce veri ön işleme basamaklarından gerçirilir ve model oluşturularak tahmin değerleri elde edilir.
train=pd.read_csv('/kaggle/input/fashionmnist/fashion-mnist_train.csv',dtype=np.float32)
train.head()

test=pd.read_csv('/kaggle/input/fashionmnist/fashion-mnist_test.csv',dtype=np.float32)
test.head()

Bu kısımda Normalizasyon için 255(toplam piksel degerleri sayısı) bölünerek gerçekleştirilmiştir.
target_numpy=train.label.values
features_numpy=train.iloc[:,train.columns !="label"].values/255
Veri setini sklearn kütüphanesi kullanarak %80 train,%20 test olarak bölünmüştür.
features_train,features_test,target_train,target_test=train_test_split(features_numpy,
target_numpy,
test_size=0.2,
random_state=42) Bölümlere ayrılan veri setleri pytorch kütüphenesinin kullanabilmesi için Tensor dönüştürülmesi gerekmektedir. Bunun için "from_numpy" kullanılmaktadır. "type(torch.LongTensor) büyük veri setlerin de kullanılmaktadır."
featuresTrain=torch.from_numpy(features_train)
targetTrain=torch.from_numpy(target_train).type(torch.LongTensor)
featuresTest=torch.from_numpy(features_test)
targetTest=torch.from_numpy(target_test).type(torch.LongTensor)
Batch_size: Veri kümesini kaç gruba bölmesi gerektigi belirtilir. number_of_iteration= Kaç iterasyon çalıştırılmsı gerektiği num_epochs= 1 epoch da toplam iterasyonun,toplam futures/batch_size bölünmesidir.
batch_size=300
number_of_iterarion=30000
num_epochs=number_of_iterarion/(len(features_train)/batch_size)
num_epochs=int(num_epochs)
train=torch.utils.data.TensorDataset(featuresTrain,targetTrain)
test=torch.utils.data.TensorDataset(featuresTest,targetTest)
Veri ön işleme kısmında son adım olarak tensor dönüştürülen verilerin pytorch tarafından kullanılabilmesi için DataLoader olarak depolanması gerekmektedir. “shuffle” datayı karıştırıp karıştırılmamsı için kullanılmaktadır.
train_loader=DataLoader(train,batch_size,shuffle=False)
test_loader=DataLoader(test,batch_size,shuffle=False)
import matplotlib.pyplot as plt
plt.imshow(features_numpy[1].reshape(28,28))
plt.axis("off")
plt.savefig("graph.png")
plt.show()

Bu aşamada artık model oluşturulmaya başlanır. Logistic regression da linear regression gibi kullanılıp sonrasında bir activation fonksiyonu kullanarak farklılaşmaktadır. Bu da genellikle “softmax” fonksiyonudur. O yüzden model kurulurken linear gibi düşünülebilir. Loss degeri için “CrossEntropyLoss” kullanılır. Bunun sebebi ise çoklu sınıflandırma problemlerinde tercih edilir.
class LogisticRegModel(nn.Module):
def __init__(self,input_dim,output_dim):
super(LogisticRegModel,self).__init__()
self.linear=nn.Linear(input_dim,output_dim)
def forward(self,x):
out=self.linear(x)
return out
input_dim=28*28
output_dim=10
#Model
model=LogisticRegModel(input_dim,output_dim)
#Loss
error=nn.CrossEntropyLoss()
#optimizer
learning_rate=0.001
optimizer=torch.optim.SGD(model.parameters(),lr=learning_rate)
Model oluşturulduktan sonra Traning işlemine geçilebilir.
count=0
loss_list=[]
iteration_list=[]
for epoch in range(num_epochs):
for i,(images,labels) in enumerate(train_loader):
#variables
train=Variable(images.view(-1,28*28))
labels=Variable(labels)
#clear gradient
optimizer.zero_grad()
#Forward
outputs=model(train)
#softmax and cross entropy loss
loss=error(outputs,labels)
#gradient hesapla
loss.backward()
#update parameters
optimizer.step()
count +=1
#Tahmin
if count % 50 == 0:
correct=0
total=0
#Tahmin test veri seti
for images,labels in test_loader:
test=Variable(images.view(-1,28*28))
#Forward
outputs=model(test)
#En iyi tahmin degeri
predicted=torch.max(outputs.data,1)[1]
#toplam labels
total += len(labels)
#toplam dogru tahmin
correct +=(predicted == labels).sum()
accuracy= 100 * correct / float(total)
loss_list.append(loss.data)
iteration_list.append(count)
if count % 500 == 0:
print('Iteration {} Loss {} Accuracy {}%'.format(count,loss.data,accuracy))